16.4 Алгоритм лексикографического упорядочения
Лексикографическое упорядочение
позволяет упорядочить некоторое множество слов в алфавитном порядке. В данном
случае необходимо сравнивать поддеревья, в узлах которых записаны некоторые
слова (множество нетерминальных и терминальных слов). Поддеревья сравниваются
следующим образом: производится одновременно левосторонний обход первого и
второго поддеревьев и сравниваются слова, записанные в текущих узлах. Если
слова равны, то производится переход к рассмотрению следующих узлов. Если
неравны, то обход прекращается и определяется отношение > или < для двух
сравниваемых поддеревьев. Алгоритм лексикографического упорядочения выражения
состоит из двух составляющих:
1)алгоритм упорядочения
мультипликативных составляющих (упорядочиваются все сыновья узлов <T>.
Назовем его TSort);
2)алгоритм упорядочения аддитивных
составляющих (упорядочиваются все сыновья узлов <E>. Назовем его DSort).
Алгоритм упорядочения DSort
первоначально упорядочивает узлы <D> рассматриваемого узла <Т> по
операции. Все узлы <D> со знаком умножения переводит влево, а с делением
вправо. И далее производит попарное сравнение поддеревьев <D> и
перестановку, если <D1> > <D2> сначала для умножения, а потом
для деления. Например, b/e * a/c будет преобразовано в b * a/e/c,
а затем в a * b/c/e.
Алгоритм упорядочения TSort
аналогичен алгоритму Dsort, только вместо умножения ставится плюс, вместо
деления - минус и рассматриваются поддеревья узлов <T>.
Тогда работу всего алгоритма
упорядочения можно рассмотреть на следующем примере: пусть имеется два
выражения: c * b + a и a + c * b, тогда после работы алгоритма DSort
получим b * c+a и a+b * c , а после работы алгоритма TSort получим a + b
* c и a + b * c. Процесс преобразования синтаксических деревьев показан
на рис.15.2
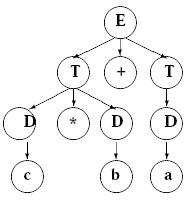 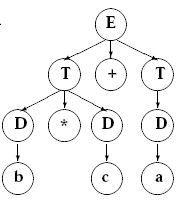 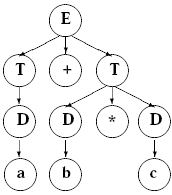
рис.15.2 Пример преобразования синтаксического дерева при сортировке узлов
Свойства алгоритма сортировки
основаны на использовании ASCII-кода. Если в качестве алфавита для сравнения
строк символов выбрана ASCII-таблица, то после применения алгоритма сортировки:
1)константы
становятся перед неизвестными;
2)выражения
в скобках становятся перед константами;
3)все
неизвестные упорядочиваются в алфавитном порядке (в соответствии с латинским
алфавитом).
|