Кодирование речи коэффициентами линейного предсказания (КЛП)
Кодирование речи коэффициентами линейного предсказания опирается на теорию статистического анализа временных рядов. Временной ряд - это последовательность наблюдений (отсчетов), упорядоченная во времени.
Суть метода заключается в следующем. Пусть имеется последовательность отсчетов (выборки) речевого сигнала: ![]() ,
, ![]() ,...
,...![]() . Для этой выборки вычисляется «взвешенное среднее» значение. Для интервала 1020 мс считают неизменными статистические свойства речевого сигнала. Этот интервал кодируют набором коэффициентов
. Для этой выборки вычисляется «взвешенное среднее» значение. Для интервала 1020 мс считают неизменными статистические свойства речевого сигнала. Этот интервал кодируют набором коэффициентов ![]() , который минимизирует среднеквадратическую ошибку предсказания, т.е. сводит к минимуму ошибку предсказания между исходным и сглаженным рядом. Вычисление коэффициентов представляет весьма трудоемкий процесс (решаются разностные уравнения методом наименьших квадратов).
, который минимизирует среднеквадратическую ошибку предсказания, т.е. сводит к минимуму ошибку предсказания между исходным и сглаженным рядом. Вычисление коэффициентов представляет весьма трудоемкий процесс (решаются разностные уравнения методом наименьших квадратов).
Практически интервал квантования обычно составляет 50100 мкс, число отсчетов 100200, число коэффициентов в пределах 4-14.
Принцип КЛП-анализа и кодирования поясняет структурная схема, приведенная на рис. 8.14.
В итоге КЛП-анализа ИКМ-представление речи, составленное из отсчетов, следующих с частотой 1020 кГц, преобразуется в последовательность векторов параметров, следующих с частотой 50100 Гц. Это дает сжатие описания речи в 50-100 раз при хорошем качестве речи.
Данный метод синтеза речи объединяет в себе достоинства метода ИКМ и формантного синтеза. При КЛП-синтезе происходит реализация модели речеобразования. В качестве речевого тракта используют линейные рекурсивные фильтры. Связь отдельных разрядов кадра управляющих параметров с элементами структуры КЛП-синтезатора показана на рис. 8.15.

Рис. 8.14 - Структурная схема кодирования речи КЛП
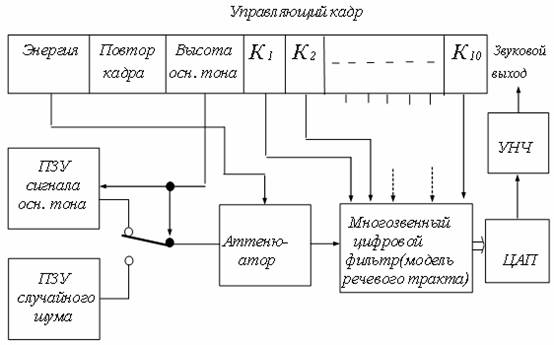
Рис. 8.15 - Структурная схема КЛП-синтезатора речи
Десять последних элементов кадра КЛП соответствуют коэффициентам, которые используются в цифровом многозвенном фильтре для генерации речи. Для практической реализации используют специальные вычислительные или программируемые процессоры сигналов, так как быстродействия обычных процессоров недостаточно.
Этот метод сложен в реализации, так как требует высокоскоростной элементной базы. Однако метод считается наиболее перспективным, поскольку он опирается на хорошее понимание процессов речеобразования. Возможность управлять параметрами модели позволяет осуществлять согласование звуков и слов по уровню энергии, по темпу, по тональному рисунку. Это делает возможным синтез сложных высказываний из набора элементов с помощью правил.
В заключение приведем сравнительные данные основных методов синтеза речи по затратам информации (табл. 8.2) [23].
Таблица 8.2
|
Способ кодирования речи |
Затраты информации бит/с |
Примечание |
| ИКМ | (40-100)·103 | |
| Дельта-модуляция | (20-50)·103 | |
| АИКДМ | (10-25)·103 | |
| Клиппирование | (3-60)·103 | Низкое качество речи |
| Формантный анализ | (2-4)·103 | |
| КЛП-анализ | (1,2-2)·103 | |
| Фонемный метод | 50-100 |
Наименьшую скорость передачи данных, управляющих речевым синтезом речи, имеет фонемный метод. Другое, не менее важное преимущество, это возможность формировать речевые сообщения по правилам (неограниченный словарь синтезируемых слов).
Наряду с широким применением синтезаторов речи в мультимедиа, методы и средства речевого общения применяются в телефонных автоответчиках, в читающих устройствах для слепых и говорящих устройствах для немых людей, а также в современной военной технике, например, в самолетах, космических системах и т.п.